From GPT-1 to GPT-4 to see the rise of ChatGPT
Recently, OpenAI released ChatGPT, which is a model that can interact in a conversational manner. Because of its intelligence, it has been welcomed by many users. ChatGPT is also a relative of InstructGPT previously released by OpenAI. The ChatGPT model is trained using RLHF (Reinforcement learning with human feedback). Perhaps the arrival of ChatGPT is also the prologue before the official launch of OpenAI's GPT-4.
What are GPTs? From GPT-1 to GPT-3
Generative Pre-trained Transformer (GPT), is a deep learning model for text generation trained on data available on the Internet. It is used for question answering, text summarization, machine translation, classification, code generation, and conversational AI.
In 2018, GPT-1 was born, which is also the first year of the pre-training model of NLP (Natural Language Processing). In terms of performance, GPT-1 has a certain generalization ability and can be used in NLP tasks that have nothing to do with supervisory tasks. Its common tasks include:
Natural language reasoning: judging the relationship between two sentences (contains, contradicts, neutral)
Question answering and common sense reasoning: input articles and some answers, and output the accuracy of the answers
Semantic similarity recognition: determine whether the semantics of two sentences are related
Classification: Determine which category the input text belongs to
Although GPT-1 has some effect on untuned tasks, its generalization ability is much lower than that of fine-tuned supervised tasks, so GPT-1 can only be regarded as a fairly good language understanding tool rather than a conversational one. AI.
GPT-2 also arrived as scheduled in 2019. However, GPT-2 did not carry out too many structural innovations and designs on the original network. It only used more network parameters and larger data sets: the largest model total 48 layers, with a parameter volume of 1.5 billion, and the learning objective uses an unsupervised pre-training model for supervised tasks. In terms of performance, in addition to comprehension, GPT-2 has shown a strong talent for the first time in terms of generation: reading summaries, chatting, continuing writing, making up stories, and even generating fake news, phishing emails, or role-playing online No problem. After "getting bigger", GPT-2 did show a general and powerful ability, and achieved the best performance at that time on multiple specific language modeling tasks.
Later, GPT-3 appeared as an unsupervised model (now often referred to as a self-supervised model), which can almost complete most tasks of natural language processing, such as problem-oriented search, reading comprehension, semantic inference, machine translation , article generation, automated question answering, and more. Moreover, the model excels at tasks such as French-English and German-English machine translation tasks that are state-of-the-art, with automatically generated articles almost indistinguishable from humans or machines (only 52% correct , comparable to random guessing), and even more surprisingly, it has achieved almost 100% correctness on two-digit addition and subtraction tasks, and can even automatically generate code based on task descriptions. An unsupervised model has many functions and works well, and it seems that people see the hope of general artificial intelligence. Maybe this is the main reason why GPT-3 has such a big impact
What exactly is the GPT-3 model?
In fact, GPT-3 is a simple statistical language model. From the perspective of machine learning, the language model is the modeling of the probability distribution of word sequences, that is, using the fragments that have been said as conditions to predict the probability distribution of the appearance of different words at the next moment. On the one hand, the language model can measure the degree to which a sentence conforms to the language grammar (for example, to measure whether the reply automatically generated by the human-computer dialogue system is natural and smooth), and it can also be used to predict and generate new sentences. For example, for a segment "It's 12 o'clock at noon, let's go to the restaurant together", the language model can predict the words that may appear after "restaurant". A general language model will predict that the next word is "eat", and a powerful language model can capture time information and predict the word "eat lunch" that fits the context.
Generally, whether a language model is strong or not mainly depends on two points: First, whether the model can use all the historical context information. In the above example, if the long-distance semantic information of "12 noon" cannot be captured, the language model is almost impossible to predict. One word "eat lunch". Secondly, it also depends on whether there is enough rich historical context for the model to learn, that is to say, whether the training corpus is rich enough. Since the language model belongs to self-supervised learning, the optimization goal is to maximize the language model probability of the text seen, so any text can be used as training data without labeling.
Due to the stronger performance and significantly more parameters of GPT-3, it contains more topic text, which is obviously better than the previous generation GPT-2. As the largest dense neural network yet, GPT-3 can translate web page descriptions into corresponding codes, mimic human narratives, create custom poems, generate game scripts, and even mimic the late philosophers-predicting the true meaning of life. And GPT-3 does not require fine-tuning, in terms of dealing with grammatical difficulties, it only needs some samples of output types (a small amount of learning). It can be said that GPT-3 seems to have satisfied all our imaginations for language experts.
Note: The above mainly refers to the following articles:
1. The release of GPT 4 is about to be comparable to the human brain, and many bigwigs in the circle can't sit still! - Xu Jiecheng, Yun Zhao - Public Account 51 CTO Technology Stack - 2022-11-24 18: 08
2. This article answers your curiosity about GPT-3! What is GPT-3? Why do you say it is so good? -Zhang Jiajun, Institute of Automation, Chinese Academy of Sciences Published in Beijing 2020-11-11 17: 25
3.The Batch: 329 | InstructGPT, a friendlier and gentler language model-public account DeeplearningAI-2022-02-07 12: 30
Problems with GPT-3
But GTP-3 is not perfect. One of the main problems that people are most worried about artificial intelligence is that chatbots and text generation tools are likely to learn all texts on the Internet regardless of their quality and quality. Then produce wrong, maliciously offensive, or even offensive language output, which will fully affect their next application.
OpenAI has also proposed that a more powerful GPT-4 will be released in the near future:

Comparing GPT-3 to GPT-4, the human brain (Image credit: Lex Fridman @youtube)
It is said that GPT-4 will be released next year. It can pass the Turing test and be so advanced that it is indistinguishable from humans. In addition, the cost of introducing GPT-4 for enterprises will also drop on a large scale.
ChatGP and InstructGPT
When it comes to Chatgpt, let's talk about its "predecessor" InstructGPT.
In early 2022, OpenAI released InstructGPT; in this study, compared to GPT-3, OpenAI uses alignment research (alignment research) to train a language model that is more realistic, less harmful, and better follows user intent InstructGPT, InstructGPT is a fine-tuned new version of GPT-3 that minimizes harmful, inauthentic, and biased output.
How InstructGPT works
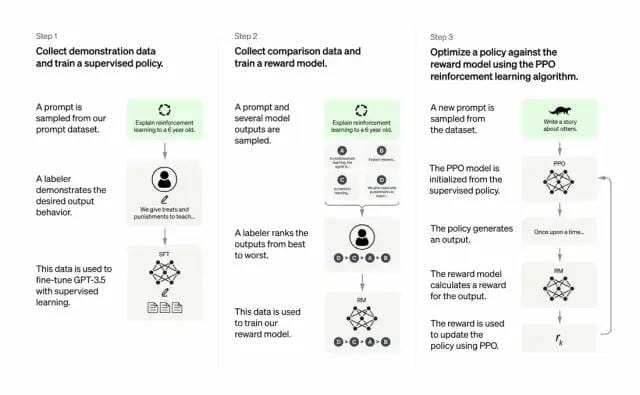
Developers do this by combining supervised learning + reinforcement learning from human feedback. to improve the output quality of GPT-3. In this type of learning, humans rank the potential outputs of models; reinforcement learning algorithms reward models that produce material that resembles higher-level outputs.
The training dataset begins with the creation of prompts, some of which are based on input from GPT-3 users, such as “tell me a story about a frog” or “explain the moon landing to a 6-year-old in a few sentences”.
The developer divides the prompt into three parts and creates responses for each part differently:
Human writers respond to the first set of prompts. The developers fine-tuned a trained GPT-3, turning it into InstructGPT to generate existing responses to each prompt.
The next step is to train a model to give higher rewards for better responses. For the second set of cues, the optimized model generates multiple responses. Human raters rank each response. Given a prompt and two responses, a reward model (another pre-trained GPT-3) learned to compute higher rewards for highly rated responses and lower rewards for low rated responses.
The developers further fine-tuned the language model using a third set of hints and a reinforcement learning method called Proximal Policy Optimization (PPO). When prompted, the language model generates a response, and the reward model rewards it accordingly. PPO uses rewards to update the language model.
Reference for this paragraph: The Batch: 329 | InstructGPT, a friendlier and gentler language model-public account DeeplearningAI- 2022-02-07 12: 30
Where is it important? The core lies in - artificial intelligence needs to be responsible artificial intelligence
OpenAI's language model can help the field of education, virtual therapists, writing aids, role-playing games, etc. In these fields, the existence of social bias, misinformation and poisonous information is more troublesome, and the system that can avoid these defects is more capable. usefulness.
What is the difference between the training process of Chatgpt and InstructGPT?
Overall, Chatgpt, like InstructGPT above, is trained using RLHF (Reinforcement Learning from Human Feedback). The difference is how the data is set up for training (and thus collection). (Explain here: the previous InstructGPT model gave an output for one input, and then compared it with the training data. If it was right, there would be rewards and if it was wrong, there would be punishment; the current Chatgpt is one input, the model gives multiple outputs, and then people give Sort the output results, let the model sort these results from "more human-like" to "nonsense", and let the model learn the way humans sort. This strategy is called supervised learning. This paragraph thanks to Dr. Zhang Zijian)
What are the limitations of ChatGPT?
as follows:
a) During the reinforcement learning (RL) phase of training, there is no specific source of truth and canonical answers to your questions, to answer your questions.
b) The trained model is more cautious and may refuse to answer (to avoid false positives for hints).
c) Supervised training can mislead/bias the model towards knowing the ideal answer, instead of the model generating a random set of responses and only human reviewers picking the good/top-ranked responses
Note: ChatGPT is sensitive to wording. , sometimes the model ends up not responding to a phrase, but with a slight tweak to the question/phrase, it ends up answering correctly. The trainer tends to prefer longer answers because these answers may seem more comprehensive, leading to a tendency towards more verbose answers, as well as overuse of certain phrases in the model, and if the initial prompt or question is ambiguous, the model Clarification will not be properly requested.
ChatGPT’s self-identified limitations are as follows.
Plausible-sounding but incorrect answers:
a) There is no real source of truth to fix this issue during the Reinforcement Learning (RL) phase of training.
b) Training model to be more cautious can mistakenly decline to answer (false positive of troublesome prompts).
c) Supervised training may mislead / bias the model tends to know the ideal answer rather than the model generating a random set of responses and only human reviewers selecting a good/highly-ranked responseChatGPT is sensitive to phrasing. Sometimes the model ends up with no response for a phrase, but with a slight tweak to the question/phrase, it ends up answering it correctly.
Trainers prefer longer answers that might look more comprehensive, leading to a bias towards verbose responses and overuse of certain phrases.The model is not appropriately asking for clarification if the initial prompt or question is ambiguous.A safety layer to refuse inappropriate requests via Moderation API has been implemented. However, we can still expect false negative and positive responses.